The PDF format is one of the most common text formats for creating agreements, contracts, forms, invoices, books, and many other documents. Each of these PDF documents consists of a variety of different elements, such as text, images, and attachments (among others). When working with a PDF document, extracting various types of elements from the document may be required. Yet, automating the extraction of valuable content from PDFs remains a challenge for many developers.
At the heart of every PDF is text, which usually makes up the majority of any single document. Therefore, extracting text from a PDF document tends to be the most common function required. Developers may want to extract all text from a document or search for specific text to find and extract within the document.
.NET PDF API libraries empower developers to unlock PDF content seamlessly by parsing and extracting PDF data and elements. This sought-after capability streamlines workflows, from data mining to content indexing, enhancing efficiency and accuracy. In this blog, we will use the C# PDF library Document Solutions for PDF (DsPdf, formerly GcPdf) to explore the following scenarios for programmatically extracting text from PDFs:
Please refer to the documentation and demo quick start for a clear understanding of how to start working with DsPdf. To follow along, download this finished .NET 8 C# sample application.
Efficiently extract all text content from a PDF document using C# by invoking the GetText method in the GcPdfDocument class. This method navigates through the structure of the PDF, gathering text from various locations and organizing it into a unified string. The extracted text can be used for multiple tasks, such as data analysis and content manipulation.
static void extractTextFromEntirePDF() < Console.WriteLine("Extract All Text from a PDF File"); using (var fs = new FileStream(Path.Combine("Consulting_Agreement.pdf"), FileMode.Open, FileAccess.Read)) < // Initialize the DsPdf document instance var doc = new GcPdfDocument(); // Load sample PDF file doc.Load(fs); // Extract All text from PDF document var text = doc.GetText(); // Display the results Console.WriteLine("PDF Text: \n \n" + text); >>
Using the above C# code, the text from each page within the PDF will be extracted and visible in the console:
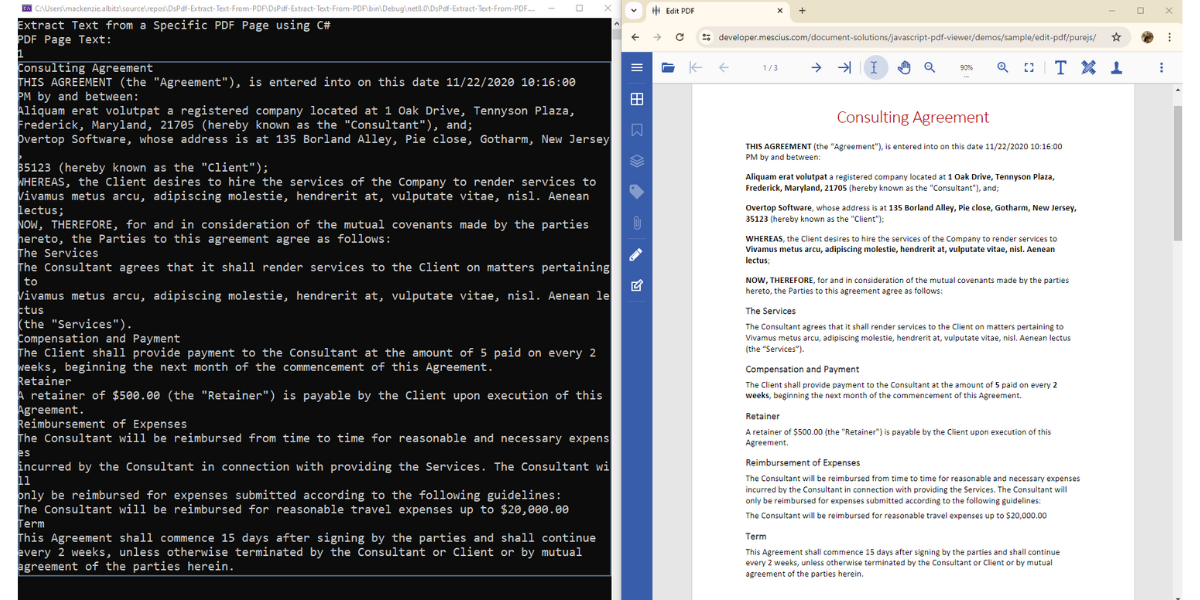
Diving deeper into PDF text extraction, this code snippet showcases how to target and extract text from a specific page within a PDF document using C#. By invoking the GetText method of the Page class, developers can pinpoint the desired page's content. Leveraging the Pages property of the GcPdfDocument class grants easy access to individual pages. In this example, text extraction from the first page is demonstrated. Harnessing this capability enables precise text retrieval for tailored analysis and manipulation within C# applications.
static void extractTextFromSpecificPDF() < Console.WriteLine("Extract Text from a Specific PDF Page using C#"); using (var fs = new FileStream(Path.Combine("Consulting_Agreement.pdf"), FileMode.Open, FileAccess.Read)) < // Initialize the DsPdf document instance var doc = new GcPdfDocument(); // Load sample PDF file doc.Load(fs); // Extract specific page text - this example targets the first page var pageText = doc.Pages[0].GetText(); // Display the results Console.WriteLine("PDF Page Text: \n" + pageText); >>The screenshot below shows the text extracted from the first page of the PDF file using the C# code above:
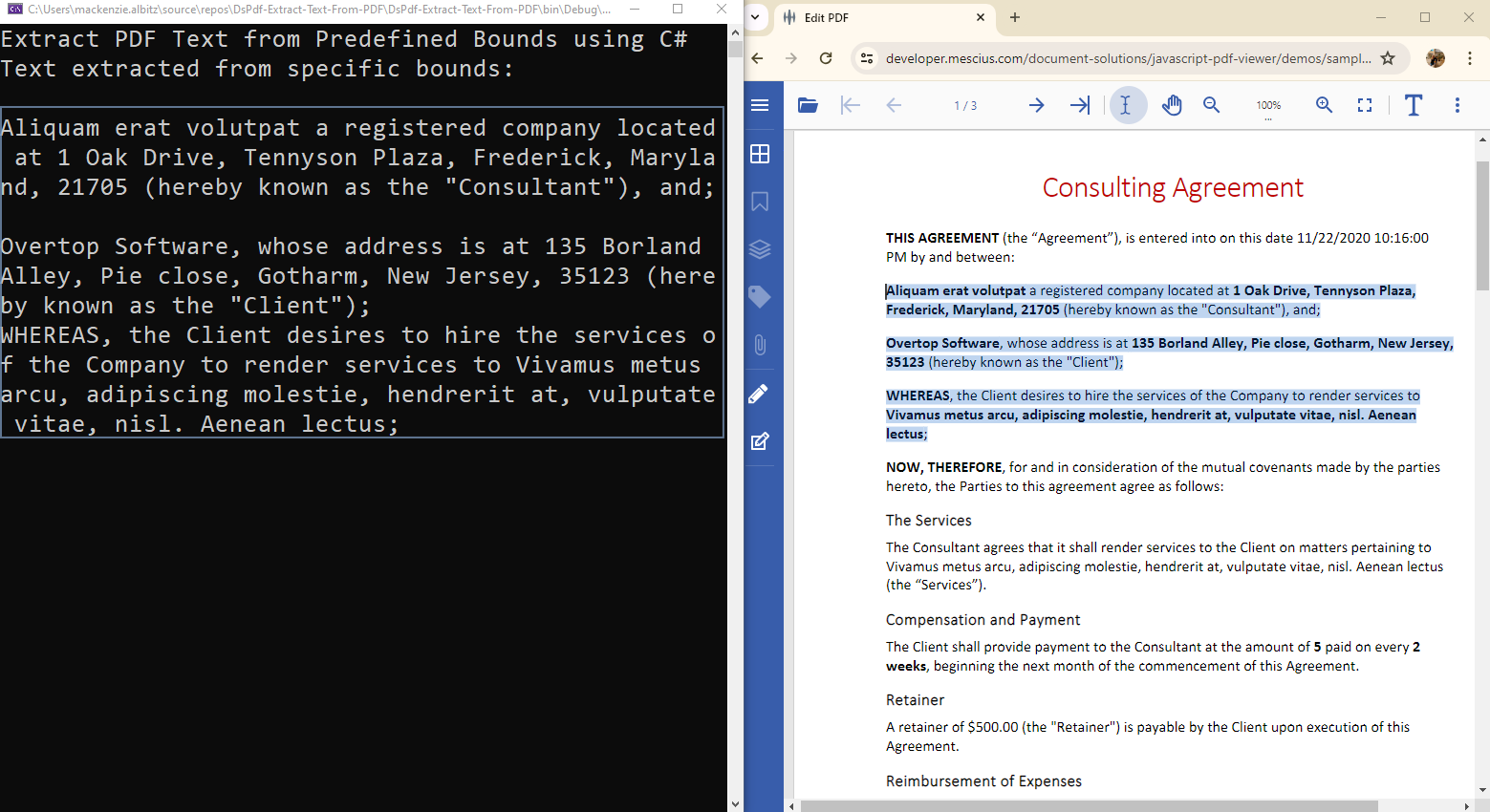
In this segment, we delve into extracting text from specific predefined regions within a PDF document using C#. The GetTextMap method of the Page class can be utilized to obtain the text map of the page, enabling precise text extraction. With the text map, developers can pinpoint text fragments within known physical positions on the page. By defining geometric bounds and utilizing known coordinates, the HitTest method locates exact positions corresponding to these bounds on the text map.
The GetFragment method of the TextMap namespace then extracts text within these specified bounds, isolating the desired content.
static void extractPDFTextFromPredefinedBounds() < Console.WriteLine("Extract PDF Text from Predefined Bounds using C#"); using (var fs = new FileStream(Path.Combine("Consulting_Agreement.pdf"), FileMode.Open, FileAccess.Read)) < // Initialize the DsPdf document instance var doc = new GcPdfDocument(); // Load sample PDF file doc.Load(fs); // Get Page TextMap var tmap = doc.Pages[0].GetTextMap(); // Retrieve text at a specific (known to us) geometric location on the page float tx0 = 7.1f, ty0 = 2.0f, tx1 = 3.1f, ty1 = 4f; HitTestInfo htiFrom = tmap.HitTest(tx0 * 72, ty0 * 72); HitTestInfo htiTo = tmap.HitTest(tx1 * 72, ty1 * 72); tmap.GetFragment(htiFrom.Pos, htiTo.Pos, out TextMapFragment range1, out string text); // Display the results Console.WriteLine("Text extracted from specific bounds: \n \n" + text); >>
The snapshot shows the result of the C# code extracting text from specified PDF bounds:
In contrast to the previous sections, which focused on extracting text, this segment covers extracting font information from the PDF document. A PDF document comprises various fonts employed for text formatting, often making it challenging to identify them through visual inspection alone. Understanding the fonts used within a document is crucial for tasks such as quick editing or font replacement.
The GetFonts method of the GcPdfDocument class offers a solution by providing a comprehensive list of all fonts utilized in the PDF document. This code snippet demonstrates leveraging this method to extract font information from the loaded PDF using C#.
static void extractFonts() < Console.WriteLine("Extract Fonts from PDF using C#"); using (var fs = new FileStream(Path.Combine("Consulting_Agreement.pdf"), FileMode.Open, FileAccess.Read)) < // Initialize the DsPdf document instance var doc = new GcPdfDocument(); // Load sample PDF file doc.Load(fs); // Extract list of fonts used in loaded PDF document var fonts = doc.GetFonts(); Console.WriteLine($"Total of fonts found in PDF file: \n"); int i = 1; foreach (var font in fonts) < Console.WriteLine($". BaseFont: ; IsEmbedded: ."); ++i; > > Console.WriteLine("Font Extracted"); >The below snapshot shows the outcome of the above C# code, extracting and writing out the fonts used within the PDF document:

This article is the first in a series of blogs that discuss how to extract PDF content using a C# PDF library. Check out the next blog in our Extracting PDF Content series, Extract Table Data from PDF Documents in C#.
Check out the full capabilities of Document Solutions for PDF – review our documentation to see the many available features and our demo explorer to see those features in action with downloadable sample projects.